chiphuyen dmls-book: Summaries and resources for Designing Machine Learning Systems book Chip Huyen, O'Reilly 2022
Table Of Content
A few of these processes include fault-tolerance, partitioning data, and aggregating data. Consistent hashing maps data to physical nodes and ensures that only a small set of keys move when servers are added or removed. Consistent hashing stores the data managed by a distributed system in a ring. This concept is important within distributed systems and works closely with data partitioning and data replication. The Hadoop Distributed File System (HDFS) is a distributed file system that handles large sets of data and runs on commodity hardware.
System Design patterns

If you want to learn more about common system design patterns, the system design interview prep course on Educative covers 20 system design patterns. Additionally, by aligning with the AWS Well-Architected principles, organizations can design and operate their RAG applications in a sustainable manner. So far, we have explored the automation of creating, deleting, and updating knowledge base resources and the enhanced security through private network policies for OpenSearch Serverless to store vector embeddings securely.
Digital Systems: From Logic Gates to Processors
Another topic explored in a scoping review was the use of AI to reduce adverse drug events. In recent years, one of the largest areas of burgeoning technology in healthcare has been artificial intelligence (AI) and machine learning. AI and machine learning use algorithms to absorb large amounts of historical and real-time data and then predict outcomes and recommend treatment options as new data are entered by clinicians.
Cracking the machine learning interview: System design approaches
Accessing data from a cache is a lot faster than accessing it from the main memory or any other type of storage. Troubleshooting techniques are employed to address issues and maintain model performance. Model lineage, which traces the origin and transformations of the data and models, helps in understanding and addressing issues that may arise during the deployment.
An 'ecosystem' of tools to boost machine learning-based design of metal–organic frameworks - Phys.org
An 'ecosystem' of tools to boost machine learning-based design of metal–organic frameworks.
Posted: Fri, 24 Mar 2023 07:00:00 GMT [source]
All of the computers in the collection share the same state and operate concurrently. These machines can also fail independently without affecting the entire system. Offline and online performance monitoring techniques are employed to assess the model’s performance. Offline monitoring involves analyzing historical data to evaluate the model’s accuracy, precision, recall, or other relevant metrics.
Data partitioning is a technique that breaks up a big database into smaller parts. This process allows us to split our database across multiple machines to improve our application’s performance, availability, load balancing, and manageability. The size and complexity of a database schema depend on the size of the project.
data:
AI system can generate novel proteins that meet structural design targets - MIT News
AI system can generate novel proteins that meet structural design targets.
Posted: Thu, 20 Apr 2023 07:00:00 GMT [source]
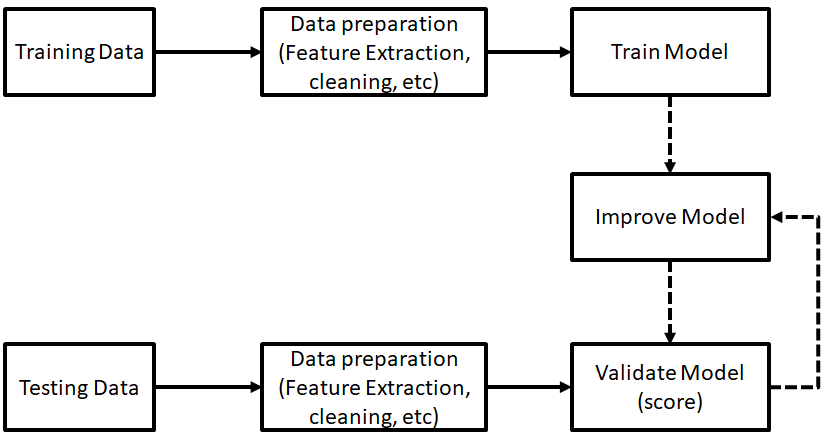
The CloudFormation template allows you to define and manage your knowledge base resources using infrastructure as code (IaC). By automating the setup and management of the knowledge base, you can provide a consistent infrastructure across different environments. This approach aligns with the Operational Excellence pillar, which emphasizes performing operations as code. By treating your entire workload as code, you can automate processes, create consistent responses to events, and ultimately reduce human errors. Offline metrics are those we used to score the model when we are building it. This is the typical scenario in research or tutorials where you split your dataset into three sets train, eval, and test.
Training is reproducible-training twice on the same data should produce two identical models. Generally, there might be some variations based on the precision of the system/infra used. Model quality is sufficient on important data slices-model performance must be vetted against sufficiently representative data. The impact of model staleness is known-how frequently re-train models based on changes in data distribution should be known to serve the most updated model in production. Offline and online metrics correlate– model metrics (log loss, mape, mse) should well correlated with the objective of application e.g. revenue/cost/time.
As these ML applications and systems continue to mature and expand, we need to begin thinking more deeply about how we design and build them. Machine learning system design is the process of defining the software architecture, algorithms, infrastructure, and data for machine learning systems to satisfy specific requirements. The Problem Navigation phase plays a crucial role in setting the foundation for a successful project. It involves visualizing and organizing the entire problem and solution space, allowing stakeholders to gain a comprehensive understanding of the task at hand.
It would help if you discussed with the interviewer alongside these points. Another important thing is to analyze what kind of data is available to you and argue if there is enough versatility. You should be aware of the implications of the imbalanced dataset in ML and address it if need be. Make sure the positive and negative samples are balanced to avoid overfitting to one class. Also, there shouldn't be any bias in the data collection process.
Assume that there are two ‘Michael Jordan’ entities in the given knowledge base, the UC Berkeley professor and the athlete. Michael Jordan in the text is linked to UC Berkeley professor entity in the knowledge base. Similarly, UC Berkeley in the text is linked to the University of California entity in the knowledge base. The layered/funnel modeling approach is the best way to solve for scale and relevance while keeping performance and capacity in check. You’ll start with a relatively fast model when you have the highest number of documents (e.g. 100 million documents in case of the search query “computer science”).
Docker is an open-source containerization platform that we can use to build and run containers. Docker containers create an abstraction layer at the application layer. Design patterns give us ways to build systems that fit particular use cases. They are like building blocks that allow us to pull from existing knowledge rather than start every system from scratch. They also create a set of standard models for system design that help other developers see how their projects can interface with a given system.



Comments
Post a Comment